What is Supervised Learning

Intro
In this article, I'm going to be talking about supervised learning, its definition, its importance, and its use cases, so sit tight!
What is Supervised Learning?
Supervised learning is a branch of machine learning that employs the use of labelled datasets to train a model.
Let's break down this definition.
The general idea of Machine Learning is to train a model, which is basically a computer program used to recognize patterns in data and make decisions from said patterns.
We're training this model to analyze a set of data, draw certain conclusions from the data, then use the knowledge gained from this experience on a completely new set of data.
Note that when I talk about "data", I don't mean the type that allows you to connect with the internet and browse stuff online or anything like that. When we talk about data in Machine Learning, we're talking about information.
Information related to a particular case or scenario which is represented in either tabular or graphical form.
For example, If I took a survey that required me to fill in information like my age, gender, and the number of meals I eat per day, it would look something like this:

And if this table contained similar information for about 5 more people (or anything more than one, really), we then refer to it as a dataset.
Which will then look something like this:
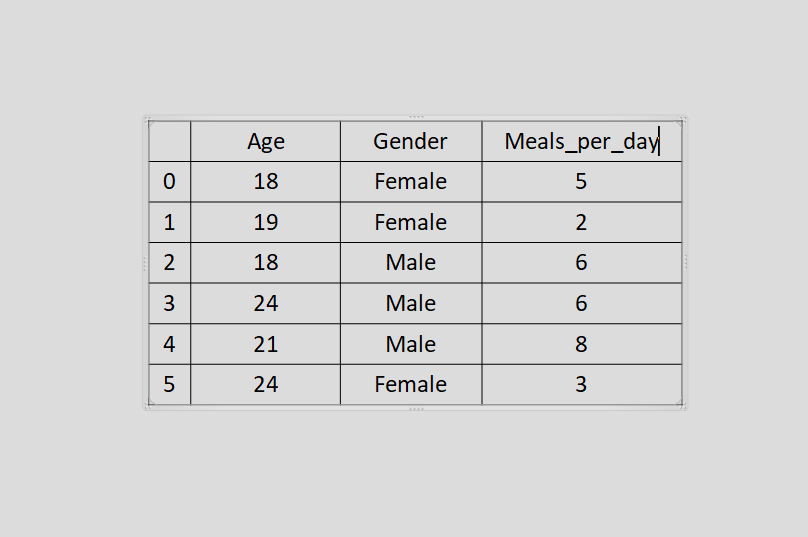
Hence, a "dataset" is simply defined as a collection or set of data.
Let's look back to the definition of Supervised Learning where we said it makes use of labeled datasets.
What differentiates Supervised Learning from the other types of Machine Learning is that the datasets for Supervised Learning come with "labels", unlike the other types of Machine Learning, which are Unsupervised Learning and Reinforcement Learning.
We'll take another example to properly understand what I mean by "labels".
I'll do this by adding a new column called "foodie" to our previous table, this shows whether the individuals in our dataset like food in a way that is slightly more than the average person or not.
So our dataset now looks something like this:
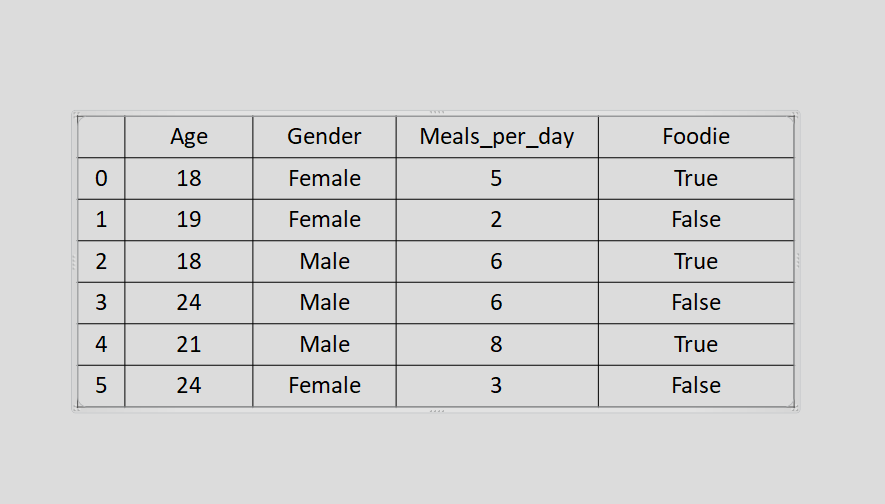
The "foodie" column here is referred to as our target or dependent variable, as its values are determined by those in the other columns. The values "True" and "False" under our target variable are what we refer to as our labels.
Each column is referred to as a feature; these are also referred to as our predictor or independent variable.
Observations are the rows beneath them that represent each person.
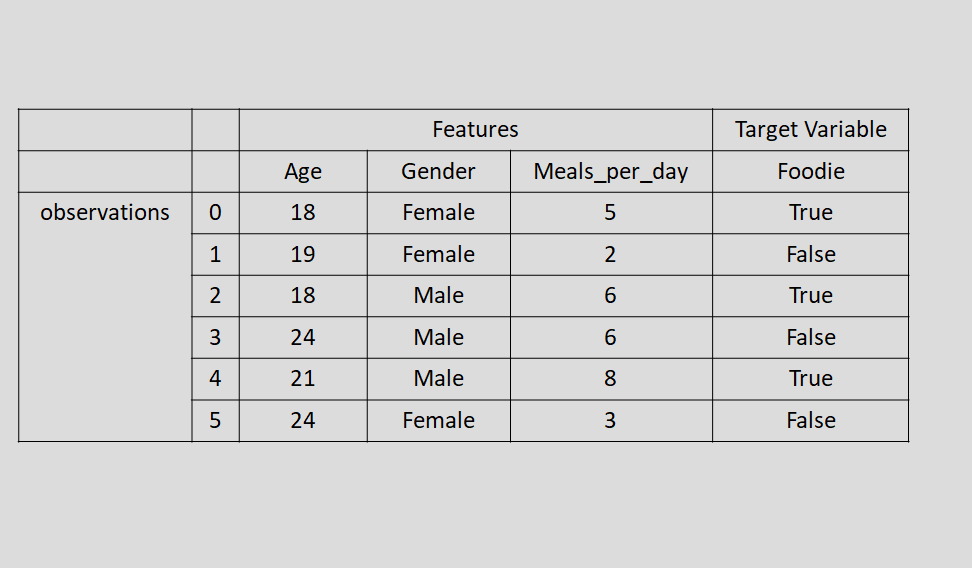
In this case, the "foodie" column is our target variable, as shown above, since that is the column we're trying to predict.
Doing this means that our model already knows exactly what to look for in another dataset after analyzing this one and can classify the new datasets based on the knowledge of the labelled dataset.
Meanwhile, in Unsupervised Learning, the model can only group or cluster the data together based on specific factors.
Types of Supervised Learning
Supervised Learning can be further subdivided into two types;
Classification, and
Regression
Whether our problem is a classification or regression problem is determined by the types of outcomes that are represented in the target variable of our given dataset.
1. Classification
In a classification problem, our outcomes are grouped into classes, or "categories".
Here we ask questions like, "What colour is the sky?", "What type of car would you like to drive?", "Would you like a cup of coffee?"
We should observe that the answer to each of these questions is one of two or more options, that is, either red/blue/white, Audi/Camry/Mustang, or yes/no.
Now, let's have a look at the second type of Supervised Learning technique.
2. Regression
Unlike classification, which assigns classes to the data, regression assigns a continuous variable to it.
Here we perform operations like trying to predict the worth of stocks or predicting what the increase in the price of burgers will be in the next two years based on existing data that has been fed to our model.
Considering $20,000 and $2 respectively to be the answers to the questions asked above, we observe here that our answers are in numerical form, so we should note that regression gives us values that are within a finite or infinite interval.
Advantages and Disadvantages of Supervised Learning
Also, like everything else in life, Supervised Learning has its pros and cons.
The major disadvantage of Supervised Learning being its inability to learn on its own. As explained in our examples above, Supervised Learning requires "labels".
The issue with this is that real-life data is messy and disorganised and most often than not does not come with labels. so we can see how limited this particular Machine Learning technique is.
But regardless of this major disadvantage, Supervised Learning also has lots of advantages, one of them being the clarity of the data, as we can imagine ... you know, labels and all.
Conclusion
So thats it for this article guys.
This was just a brief walkthrough of Supervised Learning. Here, I aimed more at simplifying the overall meaning of Supervised Learning and some general terms in Machine Learning than I did at going in-depth in any particular aspect.
I hope this article gave you a thorough understanding of Supervised Learning and of some terms in Machine Learning that you might not previously have fully understood as a beginner.
Thanks for reading. Like, share, and let me know what you think in the comments below.
I'd love to connect with you on Twitter @Iqmacodes and here on Hashnode too @Iqma




